
转-正则
在研发中 , 经常用到正则表达式 , 看过很多次 , 在用时却记不住 , 这里转篇结合例子讲解的文章以记录.
转自 掘金
正则表达式
1.1 基本语法
通过一张图表来对正则表达式的基本进行一个回顾
| single char | quantifiers(数量) | position(位置) |
|---|---|---|
| \d 匹配数字 | * 0个或者更多 | ^一行的开头 |
| \w 匹配word(数字、字母) | + 1个或更多,至少1个 | $一行的结尾 |
| \W 匹配非word(数字、字母) | ? 0个或1个,一个Optional | \b 单词”结界”(word bounds) |
| \s 匹配white space(包括空格、tab等) | {min,max}出现次数在一个范围内 | |
| \S 匹配非white space(包括空格、tab等) | {n}匹配出现n次的 | |
| . 匹配任何,任何的字符 |
1.1.1 single char
假设你有一段字符如下:
1 | These are some phone numbers 917-555-1234. Also, you can call me at 645.555.1234 and of course I'm always reachable at (212)867-5309. |
\w
将匹配所有word,当然,() - 等字符除外
\w\w\w
注意正则表达式是匹配一个连续串的规则,所以可以看到三个字母的单词可以匹配到,6个单词的也可以匹配到。
\s\s
匹配到一行中连续两个空格
quantifiers
假设我们有一段话:
1 | The colors of the rainbow have many colours |
我们想把所有的颜色找出来colors colours colour
答案 colou?rs? 嗯,看起来很简单,很方便。
好了,现在想要匹配一行中的4个数字,或者一行中的5个字母等,这时候用quantifiers就非常方便了。
我现在想找5个字母组成的单词
\w{5}这样可以吗?嗯..不行的,看下它匹配的内容,如下: ‘Theseare somephonenumbers 915-555-1234…’ 的确,我们模板给的很简单,它只找一行中,连续出现5个字母的序列。所以现在改进一下好了\w{5}\s为了能找到单词,所以我希望5个字母后,跟一个空格的序列,这样应该可以了吧,看下匹配情况: ‘Theseare somephonenumbers915-555-1234…’ 嗯,是的,只有目前这些方法,是做不到的。 所以,我们需要第三个工具 “position”
1.1.2 position
回到刚才的问题之前,先熟悉下^ $ 和 \b
1 | This is somthing |
来看下各种正则所匹配的内容
\w+这个应该毫无疑问,匹配所有的words^\w+多了一个^,这样子,就只能匹配到每一行开头的单词了\w+$这样就能匹配到每行的最后一个字母了
回到刚才的问题
现在想找5个字母组成的单词
就变得很简单了,使用单词结界符\b
答案就是\b\w{5}\b
1.1.3 找个电话号码
最后,找一个刚才出现的电话号123-456-1231
用以上最基本的正则方法就是 \d{3}-\d{3}-\d{4},这样就找到了。 但是有的时候,电话号码是123.456.1234 或者 (212)867-4233的结构怎么办呢?
正则表达式中的或或者其他表达方式,下面一一来介绍。
1.2 字符分类(char class)
前面记录了最基本的方法 , 接下来说一下分类符 []
这个符号用来表示逻辑关系或,比如[abc]表示a或者b或c.[-.]表示符号-或者.号(注意这里,在[]中的.号代表的就是这个符号,但是如果在其外面,表示个匹配所有。 所以如果不在[]之中,想要匹配’.’,就要通过转意符号\.)
1.2.1 分类的简单应用
字符序列:
1 | The lynk is quite a link don't you think? l nk l(nk |
正则表达式: l[yi (]nk
结果:
1 | lynk link l nk l(nk |
很容易理解的,就是表达或逻辑。
1.2.2 匹配所有可能的电话号码
好了,现在回到之前遗留的问题,有以下字段,请匹配所有可能的电话号码:
1 | These are some phone numbers 915-134-3122. Also, |
好的,一步一步来,刚才我们使用\d{3}-\d{3}-\d{4}匹配了连字符的情况。现在我们可以很轻松的把.这种情况加进去了
第一步: \d{3}[-.]\d{3}[-.]\d{4}
第二步: 为了能够匹配括号,可以使用?来,因为这是一个option选择。所以最后就成了
1 | \(?\d{3}[-.)]\d{3}[-.]\d{4} |
这里还是要说明,在[]中,特殊字符不需要转义,可以直接使用,比如[.()],但是在外面,是需要转义的\( \.等
1.2.3 []的特殊语法
刚才介绍了最简单和基本的功能,但是有些特殊的地方需要注意
1. -连接符是第一个字符时
比如[-.]的含义是连字符-或者点符.。 但是,如果当连字符不是第一个字符时,比如[a-z],这就表示是从字母a到字符z。
2. []中的^
^在之前介绍中,是表示一行开头,但是在[]中,有着不同的含义。 [ab] 表示a或者b [^ab] 啥都行,只要不是a或b(anythings except a and b),相当于取反
1.2.4 []和()
除了使用[]表示或逻辑,()也是可以的。用法是(a|b)表示a或者b
比如下面的例子,匹配所有email
1 | gaoyaqi411@126.com |
思路:
首先要想我到底相匹配什么,这里我想匹配的是
- 任何一个以words开头的,一个或更多
\w+ - 紧接着是一个
@符号\w+@ - 接着有一个或者更多的words
\w+@\w+ - 接着一个
.标点\w+@\w+\. - 接着一个
comnet或edu\w+@\w+\.(com|net|edu)
还是提醒注意第四步的\.转义符号
好了,这样几可以匹配以上的所有邮箱了。但是还有一个问题,因为邮箱用户名是可以有.的,比如vincent.ko@126.com
其实仍然很简单,修复如下: [\w.]+@\w+\.(com|net|edu)
1.2.5 总结
[]的作用,用英文表达就是”alternation”,表达一个或的逻辑;/[-.(]/在符号中的连字符-放在第一位表示连字符本身,如果放在中间,表示”从..到..”,比如[a-z]表示a-z[.)]括号中的特殊符号不需要转义,就表示其本身[^ab]
括号中的^表示非,anythings exceptaandb(a|b)也可表示选择,但是它有更强大的功能….
所以,()的强大功能是什么呢? 分组捕获,这对序列的替换、交换是很有帮助的。 后面一节进行学习记录
1.3 分组捕获(capturing groups)
什么是分组捕获,现在回到之前电话号码的例子
1 | 212-555-1234 |
按照之前的做法\d{3}-\d{3}-\d{4},这种匹配的方式,是将整个电话号码作为一个组(group)匹配起来。 我们把212-555-1234这样的叫Group0。
这个时候,如果我们加了一个括号\d{3}-(\d{3})-\d{4},那么匹配到的555就叫Group1。 以此类推,如果有两个小括号\d{3}-(\d{3})-(\d{4})那么分组就是下面的情况:
1.3.1 选择分组
现在组已经分好,那么如何选择已经匹配的分组?
这里有两种方法,第一种使用$符号,比如$1 代表555,$2代表1234;第二种,使用\,比如\1代表555。两种的使用场景不一样,先讲$
现在为了满足最开始的要求,我们可以这么做
1 | reg: \(?(\d{3})[-.)]\d{3}[-.]\d{4} |
1.3.2 实景训练
1. 现在有一个名单列表 , 但是姓和名是反过来的, 需要调正
1 | shiffina, Daniel |
实现方法:
1 | reg: (\w+),\s(\w+) |
注意:$0 是所有匹配到的,所以第一个加括号的是$1
2. 匹配markdown中的link标签,并替换为html标签
1 | [google](http://google.com) |
解析: 这道题有些坑,需要慢慢来。
看到这个,第一个想考虑匹配[google]这个东西,立马想到正则表达式\[.*\]。 这个是巨大的坑,在当前来看,它的确能正确匹配到上面的三条。 但是如果文本是这样的:
1 | [google](http://google.com),[test] |
看到了,第一行的内容会全部匹配下来,而不能区分[google]和[test]。 之所以这样,是因为.是贪婪的,他表示所有,所有能匹配到的,所以当然也包括了],一直到这一行的最后一个],它才停止。
所以为了让它能正确匹配,需要去掉这种贪婪的属性。这里用到? 。 当?放在了quantifiers符号后,表示去掉贪婪属性,匹配到终止条件,即可停下。
\[.*?\]这样子,就可以将[google]和[test]分开
接下来完成所有内容:
1 | reg: \[(.*?)\]\((http.*?)\) |
1.3.3 使用 \ 选择器
$选择符是在替换的时候进行的标志或选择,但是如果在正则表达式本身,就要使用\选择了。比如以下的场景
1 | This is is a a dog , I think think this is is really |
我们想要匹配比如is is so so这样连续的序列,就用到了下面的表达方式: (\w+)\s\1
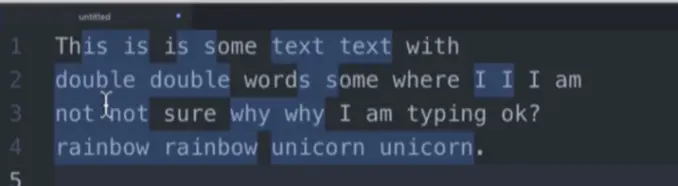
嗯,差不多达到效果,但是有一些小的bug。比如第一句话This is is a 这个就匹配不准确,会把第一个This的后面字母匹配进去。 这就用到第一节说的字符结界 \b了,就变成了\b(\w+)\s\1\b
好了,大功告成,就不贴效果图了,自行脑补就好了。
1.3.4 总结
- 分组捕获,使用()进行数据分组,编号0代表整个匹配项,选择的分组从1号开始
- 选择器可以使用
$1和\1,但是使用场景不同,\用在正则表达式自己身上 ?符号可以禁止贪婪属性,放在.*之后,表示一次匹配遇到重点就可以停止。否则将会一直向后匹配。
1.4 在JavaScript中的应用
这里就不贴了, 若需要查看 ,请参考 作者文章